

Bij kwantitatief onderzoek verzamelen onderzoekers data die vervolgens geanalyseerd worden om antwoorden te vinden op de onderzoeksvragen. Deze data zijn voornamelijk cijfermateriaal. Een voorbeeld van een kwantitatief onderzoek is een survey-studie met gesloten vragen waarvoor vooral beschrijvende statistiek wordt gebruikt. Bij beschrijvende statistiek worden data samengevat als aantallen met bijvoorbeeld percentages of gemiddelden. Bij toetsende statistiek worden formules gebruikt om bijvoorbeeld te bepalen of verschillen tussen groepen statistisch significant zijn. In beide gevallen spreken we van data-analyse.
Voordat je data kunt analyseren is het van belang de verkregen data, ook wel dataset genoemd, goed te bekijken. Er kunnen bijvoorbeeld invoerfouten ontstaan bij een variabele zoals ‘datum’ door de maand en dag om te draaien. Of bij ‘werkervaring’ door maanden en jaren als eenheden door elkaar te gebruiken. Tegenwoordig worden data veelal digitaal verzameld, waardoor foutief overtypen niet veel meer voorkomt. Toch blijft het checken van de dataset relevant. Dit kan door het databestand te openen en screenen in een statistiekprogramma als SPSS (Statistical Package for the Social Sciences).
Screenen dataset
Een eerste, snelle manier om ontbrekende gegevens op te sporen is door voor alle variabelen in een dataset het aantal ingevulde gegevens op te vragen en te bekijken. Het is van belang bij ontbrekende gegevens na te gaan of ze door toeval (random) zijn ontstaan of doordat respondenten ‘selectief’ vragen hebben overgeslagen, bijvoorbeeld vragen over seksualiteit. Afhankelijk van het soort ontbrekende gegevens zijn er verschillende manieren om hiermee om te gaan; die vallen buiten het bestek van dit artikel.
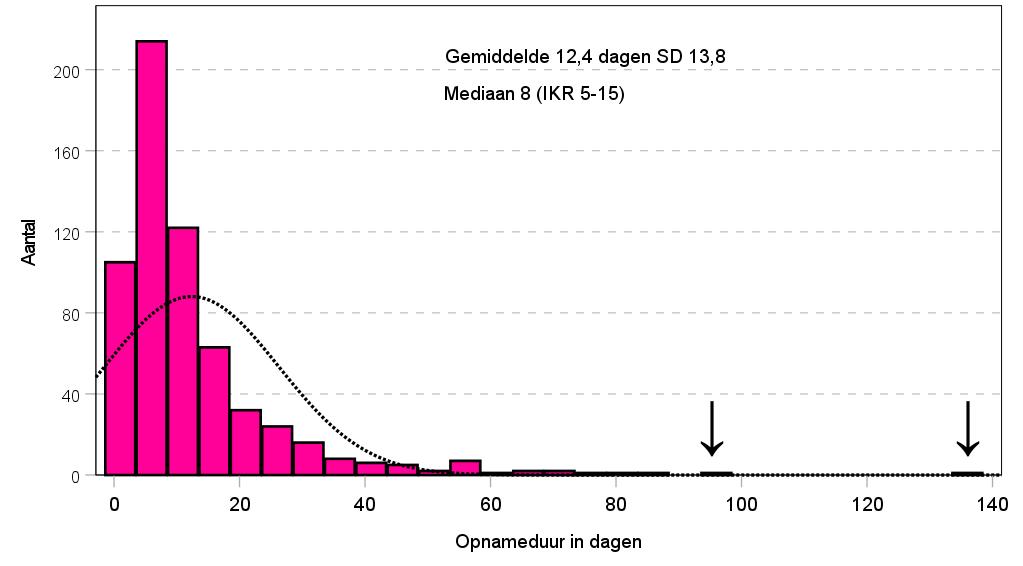
Figuur 1. Opnameduur patiënten
Tabel 1 Statistische begrippen
| Begrip | Uitleg |
| Modus | De modus is net als het gemiddelde een centrummaat. De modus is de meeste voorkomende waarde in de dataset. |
| Uitschieters | Er wordt wel onderscheid gemaakt tussen uitschieters en extreme uitschieters, afhankelijk van de afstand van de uitschieter tot de groep. IN SPSS wordt aangegeven door outliers en extremes te onderscheiden in bijvoorbeeld een boxplot. |
| Kolmogorov-Smirnov-toets | Deze toets is vernoemd naar twee Russische statistici. In 1993 ontwikkelden zij de toets om te bepalen of data een verpaalde verdeling hebben, zoals de normaalverdeling. |
| Correlatiecoëfficiënt | De lineaire samenhang kan bepaald worden door – in dit geval – de Pearson product – moment correlatiecoëfficiënt (die kan lopen tot -1 tot +1). |
Normaalverdeling
Histogrammen en puntenwolken (scatterplots) geven goed inzicht in de variabelen uit de dataset. Ze kunnen je helpen bij het kiezen van een juiste centrumwaarde (summary statistic), bijvoorbeeld een mediaan of gemiddelde gecombineerd met een spreidingsmaat (interkwartiel range of standaarddeviatie).
Is het gemiddelde hetzelfde als de mediaan? Het antwoord is ‘nee’ als er een niet-normaal verdeelde variabele is. Bij een ‘normale verdeling’ is er sprake van een symmetrische verdeling van de variabele, te herkennen aan een kerstklokvorm in een histogram met het gemiddelde precies in het midden. Een niet-normale verdeling is te zien in figuur 1. Daarin is de opnameduur van 463 patiënten weergegeven. Je kunt zien dat veel patiënten korter dan 8 dagen waren opgenomen en een kleine groep langer dan een maand, met een extreme uitschieter van 138 dagen.
De verdeling in figuur 1 wordt ook wel een ‘rechts scheve verdeling’ genoemd, waarbij het gemiddelde substantieel hoger ligt dan de mediaan. In dit geval is het wenselijk de mediaan te presenteren met de interkwartiel range en/of minimum en maximum in plaats van met het gemiddelde met de standaardafwijking. De reden: de mediaan is resistent voor dit soort scheve verdelingen. De getekende lijn weerspiegelt hoe de data eruit zouden zien als ze normaal verdeeld waren (kerstklok). Om formeel te bepalen of een variabele normaal verdeeld, is kan de Kolmogorov–Smirnov-toets worden gebruikt. Als deze toets significant is (vaak wordt p-waarde <0,05 gekozen), wordt de nulhypothese verworpen dat er sprake is van een normaalverdeling. Dit was ook het geval in ons voorbeeld en betekent dat je voor de toetsende statistiek niet-parametrische toetsen gebruikt.
Voor uitschieters (outliers) kan een duidelijke verklaring zijn (in figuur 1 een ‘lange ligger’ door complicaties of door wachttijd voor revalidatie). Maar ook kan een variabele verkeerd zijn ingevoerd, bijvoorbeeld een geboortedatum waardoor de leeftijd onmogelijk hoog is. Uitschieters die verklaard kunnen worden, dienen meegenomen te worden in de analyses. Wanneer er geen duidelijke verklaring is, wordt aangeraden een analyse met en zonder deze uitschieter te doen en de verschillen te beschrijven.
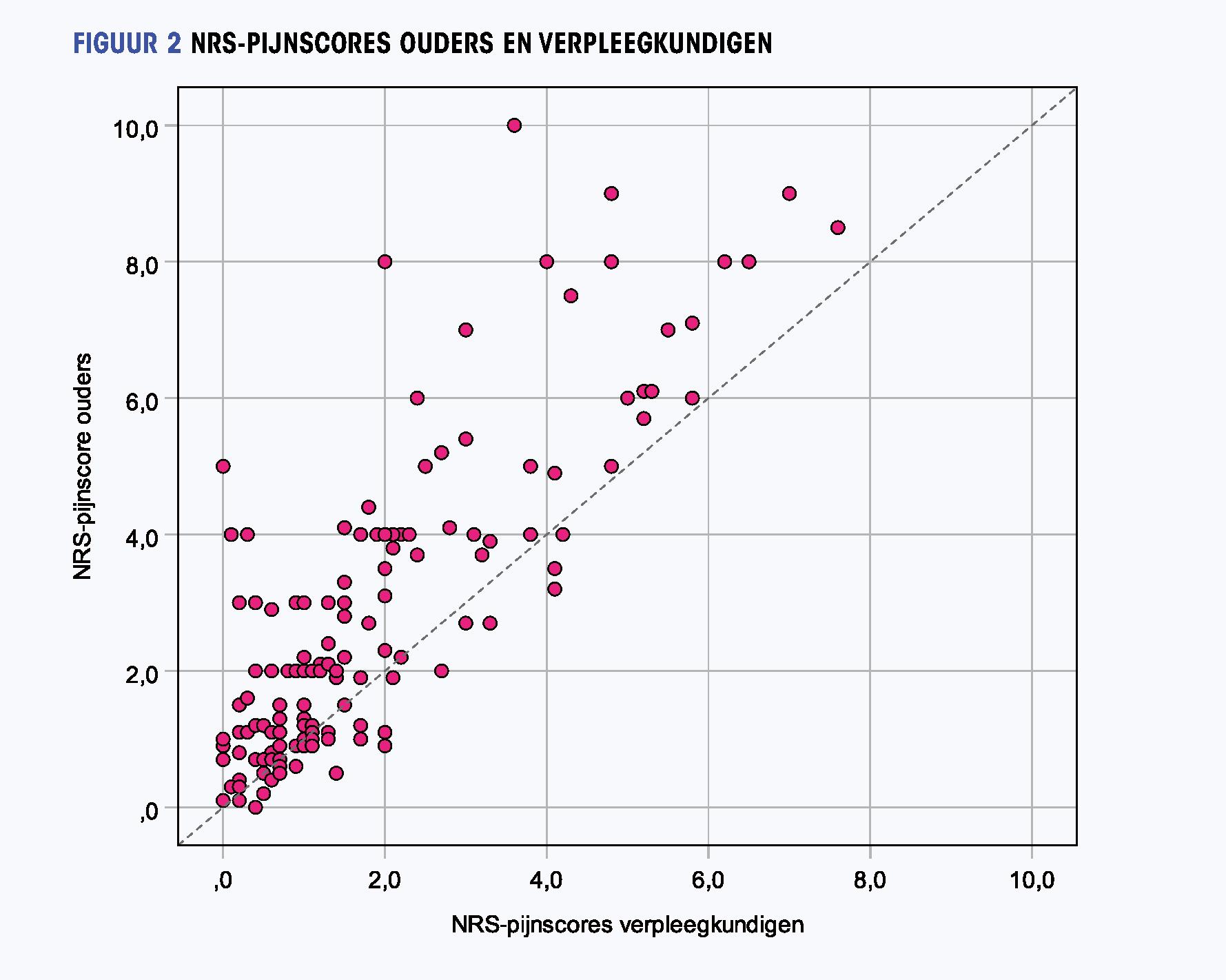
Figuur 2 NRS-pijnscores ouders en verpleegkundigen
Samenhang en verdeling
Bij het screenen van de dataset is het handig om figuren te gebruiken: het histogram in figuur 1 om de verdeling van de data te visualiseren, maar ook bijvoorbeeld een puntenwolk om de samenhang tussen twee variabelen te bekijken.
Figuur 2 toont de fictieve pijnscores die ouders gaven aan de pijn van hun geopereerde kind. Ze worden afgezet tegen pijnscores gegeven door de verpleegkundigen die voor het kind zorgden. Er is gebruikgemaakt van de numerieke ratingschaal voor pijn die van 0 (geen pijn) tot 10 (ergste pijn) loopt. De y-as en x-as geven de mogelijke minimale en maximale waarden van de variabelen aan. Pas als dat nodig is de y-as en x-as zelf aan.
‘Vóór de feitelijke toets krijg je informatie over kwaliteit van de data’
In figuur 2 is een behoorlijke lineaire samenhang te zien tussen de scores van ouders en verpleegkundigen. Door het screenen van de data krijg je dus al veel informatie over de kwaliteit en bruikbaarheid van de data voordat je feitelijk gaat toetsen. Behalve lineaire samenhang zijn ook de centrummaten en spreidingsmaten relevant om te bepalen. De stippellijn van linksonder naar rechtsboven laat met het blote oog zien dat ouders gemiddeld wat hoger scoren, aangezien de meeste punten boven deze diagonale lijn liggen. Oftewel: het kan relevant zijn niet alleen te kijken naar samenhang, maar ook naar verschillen in centrummaten en spreidingsmaten.
Als je meer wilt lezen over dit onderwerp:
– Slotboom A. Statistiek in woorden: De meest voorkomende statistische begrippen van A tot Z. 5e druk. Groningen: Wolters-Noordhoff; 2013.
– Jong de A, De Maesschalck L, Legius M, e.a. Inleiding wetenschappelijk onderzoek voor het gezondheidsonderwijs. 5e druk. Amsterdam: Reed Business Education; 2015.
– Baldi B & Moore DS. Practice of Statistics in the Life Sciences. 4th ed. London: Macmillan; 2022.